
AI能說和聽,這事兒大夥都知道。 比如足夠普及的智能音箱和手機裡的語音助手、語音輸入法。
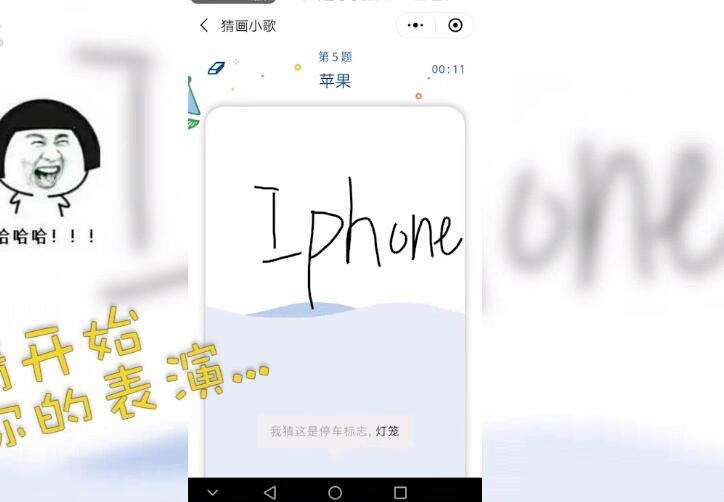
而在感知智能這個大方向裡,AI當然不只能說,同時還能看——比如說在張學友演唱會上抓個逃犯啥的。 但 AI的“看”不僅是識別人臉,同時也可以認識和判斷物體 。 比如穀歌的猜畫小程序就是依靠AI識物來實現的。
但這個領域,似乎還沒有找到太多商業化的辦法。 人臉識別可以進行大規模安防應用,但 AI識物在今天的更多應用展示,還是停留在遊戲與炫技的層面。
有沒有辦法讓AI識物的能力從“鬧著玩”,變成“能賺錢”?
國內外各種AI勢力正在努力破解這個問題。 理想總歸是美好的,而現實是緩慢摻雜著殘酷。
AI之眼,似乎還沒有給商業世界帶來足夠的魅惑。
Google Lens:下一個時代還是又一塊雞肋?
普通人能夠應用的AI識物最主要還是集成在手機攝像頭當中。 當用戶把攝像頭對準想要識別的各種東西,AI系統就會通過圖像識別以及OCR技術,給出相應的結果。
聽起來還是蠻帶感的。
目前這個領域探索幅度最大的則是AI巨頭谷歌。 在2017年I/O大會上,谷歌發布了集成在Google Photos裡的Google Lens功能。 通過這個功能,手機用戶可以將攝像頭對準各種各樣的東西,然後讓AI開口說話,告訴你ta看見了什麼。

確切來說,Lens的很多功能還是相當實用的。 比如當旅行者面對一個不知名的文物古蹟,可以用Google Lens 來獲知相關的歷史以及文化知識;對準一瓶葡萄酒,AI可以告訴你這瓶酒的各種信息,比如年份、品飲方式 、價格等等;在異國他鄉拍攝交通指示牌,AI會藉助谷歌翻譯的力量把這些信息翻譯出來。
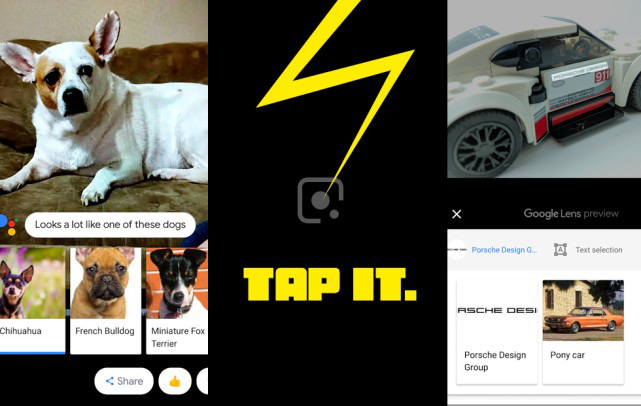
谷歌沒有公佈Lens到底能識別多少東西,但就目前情況來看,其可識別種類已經相當多。 在今年的I/O大會上,該功能還被進一步升級,可以用來拍照識別文字信息、推薦穿搭風格,甚至還能識別海報給出的藝人資料與作品。
從一年的發展來看,谷歌對於Lens的期待很大,不僅升級了它的產品地位,還不斷激發新功能,並建立與穀歌其它AI應用的聯繫。
雖然看似無所不能,但什麼都能識別的Lens也有軟肋: Lens的真實工作流程是將識別物體與數據庫進行匹配 。 換言之數據庫的大小直接影響著Lens的使用體驗。 而其技術本身的創造力則乏善可陳。 比如吳恩達去年就無情嘲笑過: Lens的識花功能其實早就是百度玩剩下的 。
目前來看,Lens在真實生活中還是“偶爾驚艷、日常癡呆”。 當然對於中國消費者的不便就更多了,比如Lens目前並不支持中文。
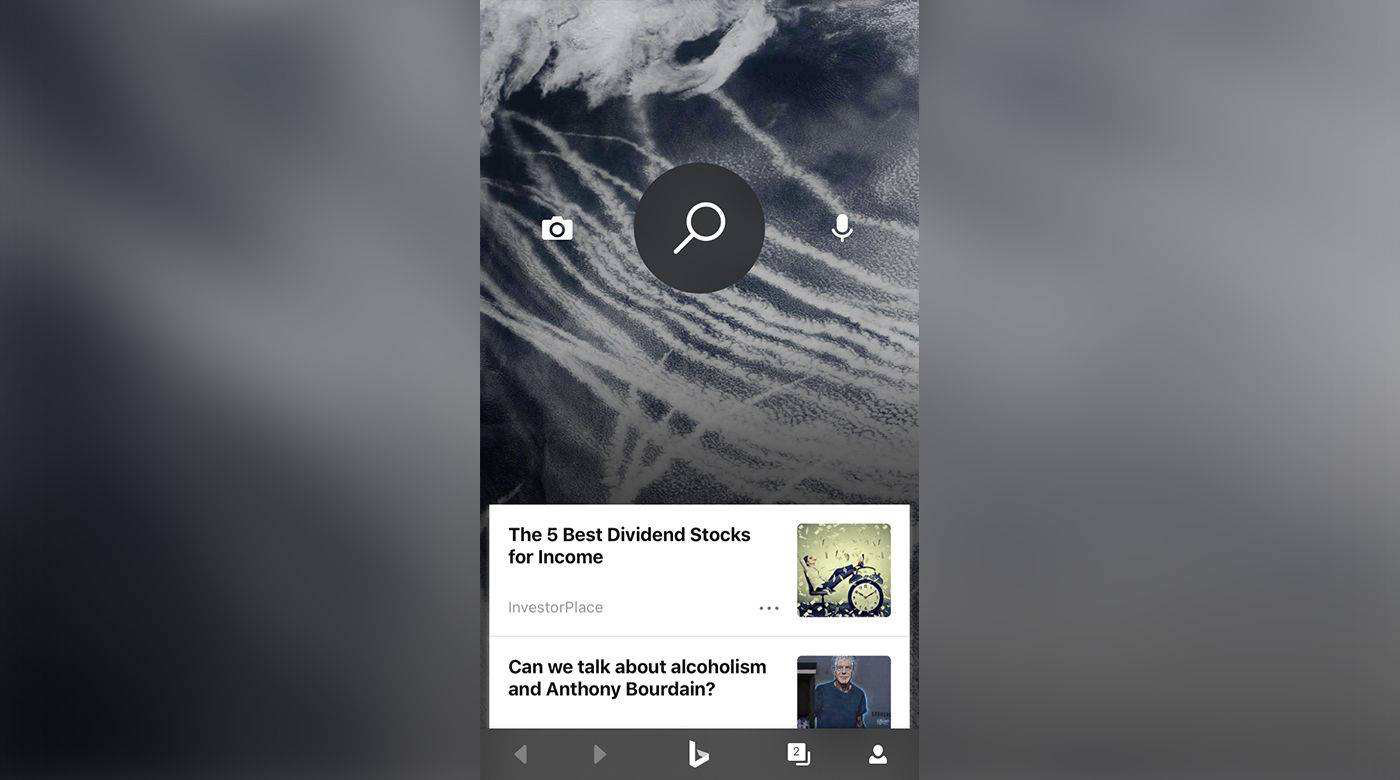
但是AI識物這條路卻是兵家必爭之地,微軟就不斷宣稱Bing搜索中的拍照搜索一點也不比Lens差。
可無論是谷歌還是微軟,都無法解決AI識圖搜索的根本問題: 用戶打開率低,商業化程度較差 。
垂直行不行? 國內的玩AI識物的幾個場景
相比於谷歌非常強勢地推出了“用我可以識別一切”的AI識物功能。 國內AI企業,無論是BAT還是創業公司,似乎都還處在這一技術應用初級開墾階段,同時也更聚焦於快速商業化的可能。 集中表現就是,國內AI識物的應用大多集中在幾個場景中:
1. 識圖購物。 這個功能已經屢見不鮮,無論是淘寶天貓還是京東,都已經投放了識圖購物的功能。 讓用戶可以通過拍照進行商品匹配, 較高效率獲知現實中商品在自家平台上的價格 。 就技術解決方案來說,由於拍攝商品往往是特徵較明顯、信息比較明確的AI識別品類,比如衣服、箱包等等,所以 這類識圖技術難度不高,加上完整的商品數據庫,並不需要很強的技術探索能力。 但缺點也很明顯,那就是用戶打開的針對性太強。
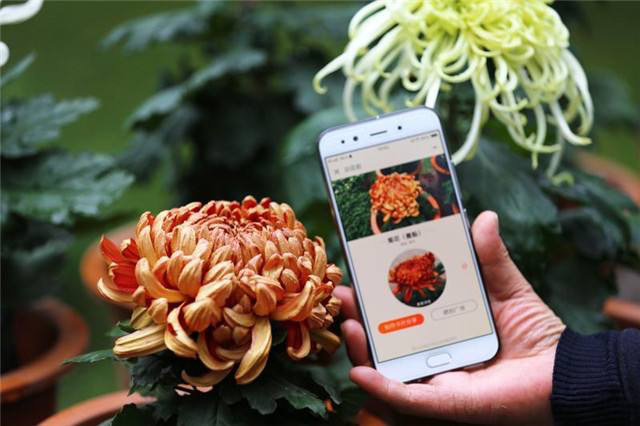
2. 識花。 各種各樣的識花軟件和產品功能早已經洗禮了中國用戶的AI常識。 目前花卉植物的AI識別能力已經被做得相當精準。 問題可能集中在 這類應用大部分還是需要調用雲端數據庫進行匹配,識別速率並不高 。 而跟識圖購物同樣的問題,在於 應用場景太狹窄 。 畢竟大家都沒空天天春遊……
3. 識字。 相比於識別花卉, 文字識別其實對於OCR糾錯、模糊識別等領域的技術挑戰更大 。 尤其是識別手寫體以及古文字。 而國內很多AI創業公司已經開始聚焦於拍照識別文字的細分應用領域。 比如我們已經能看到AI識別和錄入名片、用AI拍照並實現外文翻譯以及旅行中用AI來識別碑刻、匾額、金石文字等等為旅遊增添樂趣。
4. 批作業。 從文字識別引申出國內另一個AI識物的主要流派,是用AI來識題和批改作業。 這一領域要求足夠的數據支撐和手寫體識別能力,目前只能說還處在早期應用階段。 但 對於數學等科目來說,AI批改作業和判試卷已經基本能夠實現。 而且批作業的AI還引申出另一個應用—— 用AI來答題的考試作弊神器。
這四大領域當然各有市場可能性,但同樣的問題在於用戶可能不會花費大量時間沉浸在某個細分識別領域。 畢竟拿起手機來拍攝物體,很難變成一個隨時發生的使用習慣。
要全能還是要專精,AI識物到底應該是一門怎樣的生意呢?
想像力與困難並存的AI視覺應用
從谷歌的產品邏輯中,我們能夠發現,AI識物的出現是希望用戶能夠面對生活中各種東西:無論是貓狗、花草、海報信息還是街道建築,都拿出手機拍一下,讓AI 告訴你這背後的答案。
這個讓AI告訴我們一切的方案,出發點當然是好的。 但問題在於這 違背了大部分用戶的搜索引擎習慣,而且我們生活中遇到的絕大多數問題,都不是貨真價實擺在眼前的物體,而是某個知識、信息或者答案。 這些東西都是無法用拍照來搜索的,甚至信息的搜索強度遠遠大於對眼前真實物體的不知所措。
另一方面, AI識物的準確度還有待提高, 一兩次發現AI識別錯誤或者惡意賣萌之後,用戶自然就很難再形成嘗試衝動。
所以萬能的AI識別一切,似乎並不是這門生意的真正面目。
場景化的使用中,主要問題在於出現頻次不高,很難培養用戶的使用習慣,當然也就很難沉澱到商業化的層級當中。 目前來看,這個問題的解決方案很可能在於將AI識物的技術與某些相對高頻發生的移動互聯網需求相聯繫,在營銷的幫助下形成場景化習慣。
最有可能的當然是旅遊。 我們能夠發現,無論是識別花草,識別碑額,還是識別名勝古蹟、翻譯交通指示牌和菜單,這些都是旅行中的某個因素。 而識花用識花的APP,翻譯用翻譯機,識別古蹟再調出專門的小程序,這種體驗恐怕大部分人會覺得很煩。
因此來看,在旅行場景的統一規劃下, 整合各種AI識物應用,形成一站式旅行AI,似乎在今天比較有機會。 而BAT和旅行APP由於坐擁技術和數據優勢,似乎更有可能成為這個領域AI應用的整合者。 當然,能藉助機器視覺能力誕生新的AI巨頭,是我們更加希望看到的。

與旅行類似, AI識物的另一個機會在於兒童市場和教育市場。 兒童需要用AI來識別和感知的東西更多,而讓AI來給好奇寶寶提供關於生活中各種事物的解答,似乎也比較能夠被年輕父母所接受。 而更重要的識別類應用在於教育,無論是老師批作業,家長輔導孩子,甚至於學生尋找答案,毫無疑問都是很痛苦的過程。 能夠用AI來整合和激活這個市場,那麼前景應該是相對客觀的。
AI語音的理想狀態是通過對話來控制生活中的一切 ,包括智能家居硬件、內容、手機與購物。 AI識物的理想商業狀態也是能夠形成超級平台,讓我們在面對生活中所有不解和好奇時,都拿出手機來拍一下,讓AI告訴我們答案。
但世界搜索的需求限制以及技術目前本身的瓶頸,確實在降低這種超級平台的誕生可能性。 但在垂直場景中,毫無疑問AI識圖是能夠提升人機交互效率,並且非常酷炫有型的搜索方式,商業市場也依舊是足夠充沛的。
此外,目前也有若干問題在限制這一技術的應用度 。 比如上文說過的模糊識別精度不高問題,經常會造成用戶的需求與AI答案之間南轅北轍;再比如中文知識圖譜體係不夠完整,很多領域我們目前還沒有足夠AI回答的中文數據;還有 一個問題,是很多AI識物的場景,其實是對攝像頭的反應能力有要求的,這就放棄了很多低端機入門機搭載AI識別應用的可能性。
讓AI幫我們看世界已經足夠近,卻又比較遠。 遠近之間的故事,可能才是需要無數科技公司想破了腦袋去參悟的。
*文章為作者獨立觀點,不代表虎嗅網立場
本文由 腦極體 授權 虎嗅網 發表,並經虎嗅網編輯。 轉載此文請於文首標明作者姓名,保持文章完整性(包括虎嗅注及其餘作者身份信息),並請附上出處(虎嗅網)及本頁鏈接。 原文鏈接:https://www.huxiu.com/article/255659.html
未按照規範轉載者,虎嗅保留追究相應責任的權利
http://www.buzzfunnews.com/20180826396.html
更多有趣新聞請上:http://www.buzzfunnews.com
沒有留言:
張貼留言